
系统优化大致可以分为:业务优化、设计和程序优化、db和system优化、sql优化四个方面,这四个方面按优先级进行排列,并且越往后越不容易优化,他们之间又相辅相成、互相关联,我们优化的时候可以交替着去实施。下面着重分享一下我们在sql优化和程序优化等方面的一些经验。
一、sql优化
慢查询是大多数数据库问题的罪魁祸首,我们可以通过改善表结构设计、优化sql语句、合理的使用索引等方面来最大限度的解决这个问题,下面我们一一进行讲解。
1、 改善表结构设计
我们可以使用 procedure analyse()对当前已有应用的表类型的判断,该函数可以对数据表中的列的数据类型提出优化建议, 可以根据应用的实际情况酌情考虑是否实施优化。
select * from tbl_name procedure analyse();
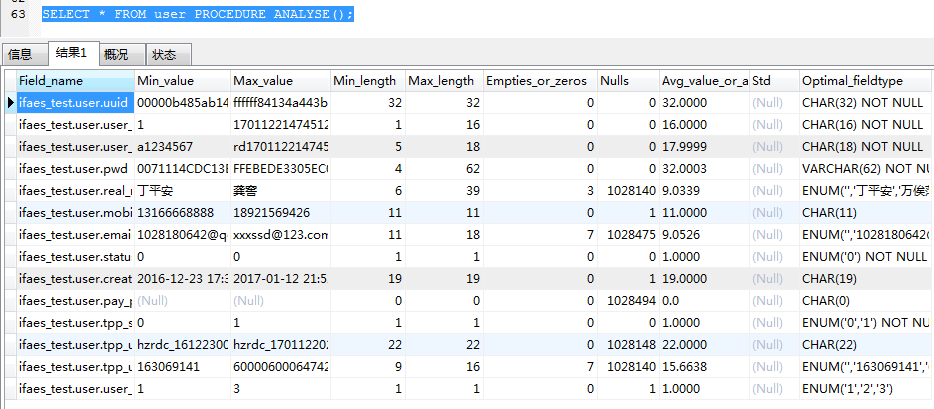 procedure analyse()是动态分析表数据得出的结果,分析需要一定的时间。分析结果展示了列名称、列的最小值、列的最大值、列最小值的长度、列最大值的长度、列中empty或0的行数,列中null的行数,平均值或者平均长度,给出的列的类型优化建议,从中我们可以看出哪些列适合哪种类型,以减少存储空间、提高查询效率。
procedure analyse()是动态分析表数据得出的结果,分析需要一定的时间。分析结果展示了列名称、列的最小值、列的最大值、列最小值的长度、列最大值的长度、列中empty或0的行数,列中null的行数,平均值或者平均长度,给出的列的类型优化建议,从中我们可以看出哪些列适合哪种类型,以减少存储空间、提高查询效率。
2、 explain查询语句
|
(product)ifaes_test@localhost [ifaes_test]> explain select * from project where uuid='000002a1155c48f389ce85a64f0e2754'; ---- ------------- --------- ------- --------------- --------- --------- ------- ------ ------- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra | ---- ------------- --------- ------- --------------- --------- --------- ------- ------ ------- | 1 | simple | project | const | primary | primary | 98 | const | 1 | null | ---- ------------- --------- ------- --------------- --------- --------- ------- ------ ------- 1 row in set (0.00 sec) |
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的sql语句,找出这些sql语句并不意味着完事了,这时我们常常用到explain这个命令来查看一个这些sql语句的执行计划,查看该sql语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
id sql执行顺序的标识,相同的id表示为同一组。sql执行顺序和id有关,id值越大越先执行,相同的id按照从上往下的顺序执行。
select_type select子句的类型,用于标识和其他子句的关联关系,常见的如simple/primary/union等类型。
(1) simple(简单select,不使用union或子查询等)
(2) primary(查询中若包含任何复杂的子部分,最外层的select被标记为primary)
(3) union(union中的第二个或后面的select语句)
(4) dependent union(union中的第二个或后面的select语句,取决于外面的查询)
(5) union result(union的结果)
(6) subquery(子查询中的第一个select)
(7) dependent subquery(子查询中的第一个select,取决于外面的查询)
(8) derived(派生表的select, from子句的子查询)
table select子句是关于哪张表的,有时会有临时表出现。

type表示mysql在表中找到所需行的方式,又称为“访问类型”。常用的类型有:const/eq_reg/ref/ range/ index / all。
const表示该表中最多有一条匹配的记录,出现在主键、唯一索引等查询语句中。
eq_reg对于每个来自前面的表的行组合,从该表中读取一行。即前表的行组合和当前sql是一一对应的关系。
ref 前表的行组合和当前sql是一对多的关系。
range使用索引来检索给定范围的行,key表示使用的索引名称。(<>、>、>=、<、<、<=、is null、between、in等等)。
index 使用索引进行检索。
all 进行完整的表扫描,即全表扫描。
possible_keys 列指出mysql能使用哪个索引在该表中找到行,方便我们合理利用索引来优化sql语句。
key 列显示mysql实际决定使用的键(索引)。如果没有选择索引,键是null。要想强制mysql使用或忽视possible_keys列中的索引,在查询中使用force index、use index或者ignore index。
key_len 列显示mysql决定使用的键长度。如果键是null,则长度为null。使用的索引的长度。在不损失精确性的情况下,长度越短越好 。
ref 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows 列显示mysql认为它执行查询时必须检查的行数。
3、 合理的使用索引
首先要说明一点,合理的使用索引可以提高检索(查询)的效率,但是插入/更新/删除等操作时都需要对索引进行维护,所以索引并不是越多越好。
在用户红包表、用户加息券表中

user_redenvelope表有主键索引,tender_id的单列普通索引,user_id和status的联合索引,use_expire_time_status和status的联合索引。下面分别说说各索引的用处,主键索引这里就不详述了。
idx_user_redenvelope_tender_id 查询投资记录所使用的红包时使用;
idx_user_redenvelope_user_id_status 查询指定用户可用红包/不可用红包时使用
idx_user_redenvelope_use_expire_time_status 处理过期红包时使用,后面会讲到如何使用索引。
用户加息券表的索引和和用户红包表的索引差不多,这里就不赘述。
和用户一一对应的记录表:user_base_info、user_cache、user_identify、user_company_info、user_score、user_vip等添加user_id唯一索引;
投资记录表project_invest、待收记录表project_collection、待还记录表project_repayment对project_id列建立普通索引,产品表product、借贷表borrow对project_id列建立唯一索引。债权相关的表和投资相关表类似。
下面举一个索引使用不当的例子:

在user_cache表总创建了两个索引:uq_user_cache_user_id针对用户id的唯一索引和idx_user_cache_user_id_user_nature是将user_id和user_nature组合在一起的联合索引。上面的查询语句中,两个索引一个也没用到。
我们来考虑一下索引的有效性,uq_user_cache_user_id索引可以用来防重并且在多数查询时可以通过user_cache.user_id=xxx来使用唯一索引,提高查询效率。另一个就是idx_user_cache_user_id_user_nature,我们的期望是想通过和user的关联来查询某一类型的用户,但是事与愿违,所以该索引是无效的。那么我们怎么做?
1、删除idx_user_cache_user_id_user_nature索引;
2、在user表添加冗余字段user_nature,或者将user_nature列直接移至user表;
4、 其他优化建议
a) 表关联查询时,能使用内连接(逗号分隔或者inner join)的尽量不使用外连接(left join or right join),能使用join的尽量不使用子查询;
查询投资记录,关联项目记录时使用内联
|
select * from project_invest i inner join project p on i.project_id= p.uuid ; select * from project_invest i left join project p on i.project_id= p.uuid ; |
查询没有进行过投资的注册用户,使用外联代替子查询:
|
select * from user where uuid not in (select user_id from project_invest ); select u.* from user u left join project_invest i on i.user_id = u.uuid and i.user_id is null; |
b) 对于排重(或分组)的sql,可以使用下面两种,推荐使用方案1
方案1:select distinct min,max from tbl;
方案2:select min, max from tbl group by min,max;
c) 索引使用最左匹配原则,在条件查询时,如果组合索引中的首列没有出现,mysql优化器将放弃使用索引。
如下的第三条语句mysql优化器将放弃使用索引
|
select * from user_redenvelope where use_expire_time>='2017-01-04 23:59:59' and use_expire_time<='2017-01-13 00:00:00' and status='0'; select * from user_redenvelope where use_expire_time>='2017-01-04 23:59:59' and use_expire_time<='2017-01-13 00:00:00'; select * from user_redenvelope where status='0'; |
d) 散列分布不均的列不推荐使用索引,比如状态列、枚举类型的列等等;
e) 尽量避免select * 操作,从库里读取的数据越多查询越慢。
f) 固定长度的效率更高,尽可能的使用非空约束(通过表结构优化来进行处理)。
二、代码优化
1、 缓存服务
对于访问频率比较高的或者不常更新的数据,我们可以考虑使用缓存服务,来提高系统的响应效率,减小数据库服务器的压力。比如前台凯发推荐首页、理财频道、投资详情页等页面。
凯发推荐首页的新手专享和精选投资列表缓存2s
|
/** * * 凯发推荐首页--新手专享投资列表 * @return * @throws exception */ @requestmapping(value="/index/getnoviceproject") @responsebody @cacheable(expire=expiretime.two_sec) public object getnoviceproject() throws exception { … } /** * * 凯发推荐首页--精选投资列表 * @return * @throws exception */ @requestmapping(value="/index/getchoiceproject") @responsebody @cacheable(expire=expiretime.two_sec) public object getchoiceproject() throws exception { …. } |
理财频道缓存5s
|
/** * 产品列表查询 * @author fangjun */ @cacheable(key = cacheconstant.key_project_list, expire = expiretime.five_sec) public page … } |
2、 队列服务
对于优先级不是特别高的操作,可以考虑将其加入队列的方式进行处理。比如前台用户注册,注册成功以后不仅需要向user、user_cache、user_company_info(user_base_info)、user_identity、user_vip、user_score、user_invite等用户相关的表中添加记录,还需要在账户中心进行注册,根据活动方案的规则发放相应的红包、加息券等操作。活动方案相对用户信息和账户信息来说显得不是那么迫切,不需要即时入库,可以考虑将活动方案加入队列服务。活动方案加入队列服务之前,用户注册的并发量一直上不去。活动方案加入队列之后,用户注册的并发可以达到30tps,用户注册的并发量有了显著的提升。
活动方案加入队列后带来了一个新的问题,就是假如后台配置的活动方案太多,队列服务又需要一个一个的进行处理,在高并发的情况下会出现大量的消息堆积。有时甚至两个小时的用户并发注册,队列服务跑一天都处理不完。
接着怎么办?拆服务
梳理活动方案的类别,将活动方案拆分成:注册送好礼--送红包、注册送好礼--送加息券、注册好友送好礼--送红包、注册好友送好礼--送加息券、注册 --送积分五个小类。然后分别如队列进行处理。
类似的,我们对调度任务的队列服务按放款、还款、项目撤销的类别进行了服务拆分。
|
private user adduserforregister(final usermodel model){ //用户相关表持久化操作… //活动方案入队列 注册的时候拆分队列 mqactplanmodel redactmodel = new mqactplanmodel(mqconstant.operate_actplan_register_gift_redpacket, user,null,null); rabbitutils.actplan(redactmodel); mqactplanmodel rateactmodel = new mqactplanmodel(mqconstant.operate_actplan_register_gift_ratecoupon, user,null,null); rabbitutils.actplan(rateactmodel); mqactplanmodel friendredactmodel = new mqactplanmodel(mqconstant.operate_actplan_register_friend_gift_redpacket, user,null,null); rabbitutils.actplan(friendredactmodel); mqactplanmodel friendrateactmodel = new mqactplanmodel(mqconstant.operate_actplan_register_friend_gift_ratecoupon, user,null,null); rabbitutils.actplan(friendrateactmodel); mqactplanmodel scoreactmodel = new mqactplanmodel(mqconstant.operate_actplan_register_score, user,null,null); rabbitutils.actplan(scoreactmodel); returnuser; } |
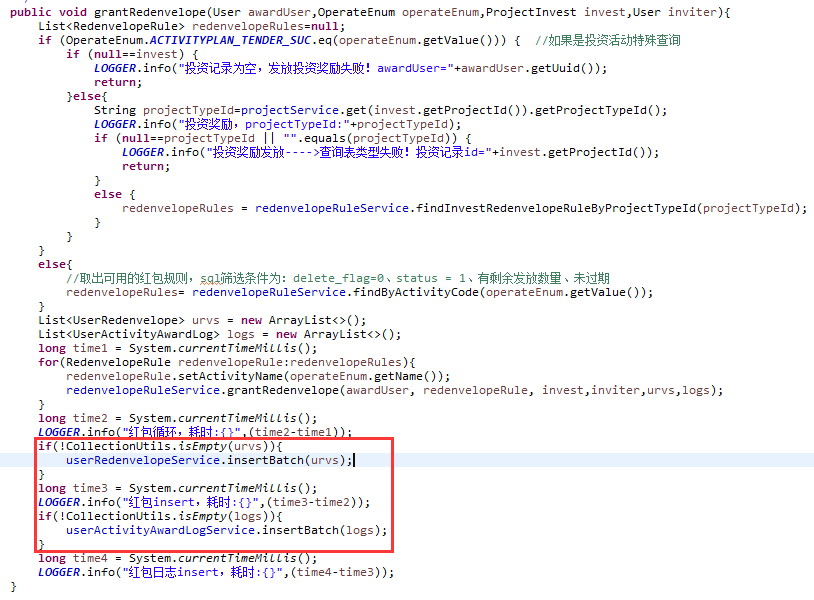
3、 单项持久化改为批量持久化
在前期的活动方案中,红包、加息券的发放是按用户和活动规则是一条条进行的,活动方案匹配成功后将红包(加息券)发放给用户,生成一条用户红包(加息券)记录和发放日志记录。跟踪队列服务发现在活动规则较多、用户注册并发量大的时候,队列的处理效率低的吓人。根据业务场景,我们将同一个用户的多个活动合并,批量持久化到数据库。在经过将队列服务拆分和单项操作改为批量操作后,活动方案的处理能力从0.2tps提升到10-30tps。
类似的,调度任务、账户中心等地也从原来的单条持久化改为批量持久化。
4、 定时任务
程序员在处理定时任务的时候喜欢简单粗暴的方式,就像这样的:
|
#将红包标记为已过期 update user_redenvelope set status=#{status} where use_expire_time < now() and status=#{prestatus} |
这个sql语句在数据量不大的时候执行没有什么问题,一旦数据量上去之后就会卡死,甚至产生死锁。
那么怎么优化?我们先看看定时器里的方法
|
@scheduled(cron = "0 */5 * * * ?") publicvoid docouponexpiredhandle() { userredenvelopeservice.expiredhandle();// 红包过期处理 userratecouponservice.expiredhandle();// 加息券过期处理 } |
上面的@scheduled注解表示这是一个定时操作,cron表达式表明每五分钟执行一次。也就是说该方法会每五分钟执行一次,发现有过期的红包或者加息券就标记为已过期。
既然是每五分钟执行一次,那么我们查询的时间范围应该是可以继续缩小的,比如查询10分钟以内已经过了有效期但状态为未过期的记录。然后将状态标记为已过期并将结果分批次批量入库。
|
/** * 红包过期处理 */ @override publicint expiredhandle() { date now = dateutils.getnow(); list list if(collectionutils.isnotempty(ids)){ for(string id:ids){ userredenvelope url = new userredenvelope(); url.setuuid(id); url.setstatus(operateenum.status_expired.getvalue()); list.add(url); } //批量更新 list for (list dao.updatebatchstatus(ls); } } return constant.int_one; } |
mapper对应的sql如下:
|
<select id="findexpirelist" resulttype="string"> select uuid from user_redenvelope where use_expire_time between #{starttime} and #{endtime} and status=#{prestatus} select>
<update id="updatebatchstatus" parametertype="java.util.list"> <foreach collection="list" item="item" open="" separator=";" close=""> update user_redenvelope set status = #{item.status} where uuid = #{item.uuid} foreach> update> |
我们总结一下:
查询一定时间范围内状态为未过期的红包记录;
将记录标记为已过期;
将红包记录分批次批量入库;
这里为了提高查询的效率,我们对use_expire_time和status创建了联合索引并且将范围查询由>=、<=调整为between and。
那么我们能不能直接将上面的查询语句调整为update语句呢?答案是:不推荐。对于数据量较大的平台,不建议直接批量更新,因为没办法确定更新记录的数量。数据量太大依然会卡死,甚至产生死锁。其他的定时操作也可以按照这样的步骤来进行优化。
另外一个优化点就是缩小事务的范围,定时任务多是批量操作。简单的定时操作通过一个update语句就能搞定,还有一些定时操作相对就复杂的多,涉及很多的业务处理,逻辑判断,而这些批量操作的数据之间又是相互隔离,互不影响的,比如订单超时处理、自动审核、自动下架等等。我们没有必要在这些定时任务的入口加上事务,只需要在处理单笔交易时加上事务支持即可。
|
//@transactional(readonly = false)//订单超时处理入口取消事务支持 publicvoid investtimeouthandle() { … }
/** * 投资超时处理,在单笔交易中添加事务支持 * @param invest */ privatevoid iteminvesttimeouthandle(outtimeprojectinvest invest){ transactiondefinition definition = new defaulttransactiondefinition(); transactionstatus ts = transactionmanager.gettransaction(definition); try { //处理超时相关业务… transactionmanager.commit(ts); } catch (exception e) { transactionmanager.rollback(ts); logger.error(e.getmessage(),e); throwe; } } |
5、 后台查询
根据多年的从业经验在关联查询这方面定了一个规则:后台的关联查询不得超过3张表。起初大家都不是很理解,总觉得规定这么死很难去实现产品经理或者客户的需求。众所周知,后台查询通常都会进行一些跨表的关联查询,有的时候为了满足业务需要甚至需要关联5、6张表进行查询,sql语句写的那叫一个漂亮,能整几十甚至上百行。但是数据量一旦上去,就卡的不行不行的。那么我们怎么去做既能保证sql高效,还能保证能够实现产品经理或者客户的需求呢?
经验一:尽量将多表改为单表查询;
拿菜单【用户积分】举例,以下为【用户积分】列表页面的截图:

我们可以看到用户积分列表页展示了用户名、总积分、有效积分、冻结积分和消费积分等信息。列表中除了用户名是user表的属性外,其他列的信息都来自user_vip表。假设我们通过将user和user_vip的关联调整为单表查询,我们该以哪张表为主进行查询呢?
方案一:分页查询以user_vip为主表,在service层通过user_vip的user_id查询出user表的用户名;
方案二:分页查询以user为主表,在service层通过user的uuid查询user_vip的相关信息;
貌似这两种方案都行的通,但是细看页面我们发现搜索框是支持根据用户名进行模糊查询的,所以方案一被否决,方案二胜出。
这个问题貌似难度不够高,假设用户提出要求,我们需要按照用户名、总积分、有效积分、冻结积分和消费积分等信息进行检索或者排序,那方案二显然不能满足需求,怎么办?
经验二:适当的时候可以考虑添加冗余字段;
接着上面的问题,测试环境的用户量已经超过一百万,关联查询显然已经不合适,那么我们就可以考虑在user_vip表中将user表的用户名列冗余添加到user_vip表中。这个例子可能不够好,我们举个相对比较恰当的例子吧。
对project(产品借贷)做了分类,我们在前台的理财频道中需要用到项目的类别名称,通过关联查询project_type表确实是一个方案,但是不够好。我们可以考虑在project表中添加类别名称列的冗余来取消对project_type表的关联查询。
经验三:通过添加索引提高查询效率;
表的数据量过大时,我们还可以采取通过添加索引的方式来提高查询效率,这里我就不展开讲解了。当然其他的优化方案在这里也可以派上用场。
6、 excel导出
excel大批量数据导出一直是我们系统的弱项,2.0里导出操作的数据量超过一万就会卡死。我们先看看excel导出经过了哪几个步骤:
1) 从数据库中查询出符合条件的记录;
2) 对记录中的数据进行加工处理,如将状态、枚举等类型转为可描述的信息等;
3) 将记录写入到文件或输出流中;
我们看到纵向操作很难去优化,那么我们分析一下数据量超过一万条就卡死的原因是什么,是在那一步产生的?
通过跟踪服务器的相关指标(线程、cpu、内存、相关服务),我们发现在做导出操作的时候,服务器的cpu和内存都飙升的很高。那么我们能不能通过调节jvm的相关参数来避免导出的时候出现卡死的现象呢?答案是:不推荐。
我们通过excel导出的步骤可以推测:导出卡死主要是因为数据量太大,导致jvm的内存爆表。那么如何优化呢?
我们在查询的时候模仿后台列表页面的分页操作,在导出的第一步将一次查询改为分页查询,每次最多读取5000条记录(每页导出的记录数根据实际情况来定)。目前我们已经做到可以支持百万级的数据导出,而不会出现卡死的现象。
除此之外,我们还做了什么?
我们发现,一般而言,导出的列都是和页面展示的列对应的,在后台通过硬编码来决定导出的列确实是一件吃力不讨好的事情,我们对需要导出的列做了封装,页面展示哪些列,导出就是哪些列,不需要在后台进行硬编码。
另外一个问题是让人头疼的状态、枚举等列在导出时的转换问题,我们定义了@dicttype的注解,在代码里将繁琐的状态、枚举等类型的信息转换全部去除。
相关推荐
携程h5性能优化实战-魏晓军
《linux 性能优化实战》案例
具体内容包括:基于用户体验的性能优化要素、前端性能优化实战、网站性能分析、服务端性能优化、tcp优化、dns优化、cdn优化、大型网站性能监控体系、大型网站容量评估、高性能系统架构模式、大促保障体系、数据分析...
该文档来自mdcc 2015中国移动开发者大会。 徐凯(鬼道) - 手机淘宝 hybrid app 性能优化实战的主题演讲,欢迎下载!
性能优化手册是一套java性能学习研究小技巧,包含内容:java性能优化、jvm性能优化、服务器性能优化、数据库性能优化、前端性能优化等。 内容包括但不限于: string 性能优化的 3 个小技巧 hashmap 7 种遍历方式...
java 性能优化实战 21 讲,java 性能优化实战 21 讲,java 性能优化实战 21 讲,java 性能优化实战 21 讲
java 大型网站性能优化实战从前端网络 cdn 到后端大促的全链路性能优化。 大型网站性能优化实战从前端网络cdn到后端大促的全链路性能优化 性能优化 网站 java 前端 服务器
│ 开篇词 java 性能优化,是进阶高级架构师的炼金石.mp4 │ 02 理论分析:性能优化有章可循,谈谈常用的切入点.mp4 │ 03 深入剖析:哪些资源,容易成为瓶颈?.mp4 │ 04 工具实践:如何获取代码性能数据?....
大型网站性能优化实战从前端网络cdn到后端大促的全链路性能优化
java秒杀系统方案优化-高性能高并发实战 java秒杀系统方案优化-高性能高并发实战
完整版,非常难得。
目录 架构改进之路 1 文档处理的改进之路 1实战项目-性能优化实战架构改进之路服务的拆分,把离线文档的生成拆了出来,变成一个单独的rpc服务。实现rpc服务
大牛-高级教程mysql性能优化实战。
flink原理、实战与性能优化.pdf
《android性能优化-大厂实战全解析》
深入剖析ios性能优化.pdf
阿里巴巴java性能调优实战
对 java 工程师而言,性能优化能力决定了你能否进入大厂或成为一名高级工程师。但性能优化的能力却极难提升,如果你缺乏正确的方法论和实战演练,则很容易事倍功半。 视频大小:1.2g
weex 架构简介和性能优化实战.pdf